DBベンチマーク祭り - TPC-C編 - (2022年 年始版)
みなさんこんにちは!
ご無沙汰してます
またまた2年後になってしまいました。
約2年前、春のDBベンチマーク祭りと称してMariaDB、MySQL、PostgreSQLそれぞれの
TPC-C(OLTP)のベンチマークを取得して比較したものを載せました。
まだまだコロナで自宅に籠ることも多い最近ですが、PCの入れ替えを行った事もあり、またまた懲りずにベンチマークをとっていきたいと思います。
実行環境
今回使用するマシンもご家庭で用意できるPCをホストにしてVMを立て、
そのVMに各OSS DBをインストールして、ベンチマークを取得しました。
〇ホストマシンのスペックはこちら
- CPU : 11th Gen Intel Core i7-1165G7 2.8GHz(8CPU)
- MEM : 32.0GB
- SSD : NVMe SSD 1TB(ADATA SX8200Pro)
- GPU : Intel Iris Xe Graphics
○VMのスペックはこちら
- CPU:4core
- メモリ:8GB
- SSD:64GB
○各RDBのバージョン
- PostgreSQL 14.1
- MySQL 8.0.27
- MariaDB 10.6.5
レギュレーション
今回定めたレギュレーションは以下の通りです
- ベンチマークにはHammerDBを使用する
- 取得するベンチマークはtpc-cを採用する
- HammerDB実行時に起動するVMは1つのみとし、他のアプリケーションは一切動かさない
- 各DBで変更するパラメータはメモリ関連のもののみ
また、レギュレーションとは別に、今回はパフォーマンスチューニングを行いました。
Postgresqlは、PGTuneを参考にしました。
MySQLおよびMariaDBは、MySQLTunerを参考にしました。
HammerDBを使用したtpc-c実行環境の構築
こちらを参考に、tpc-cベンチマーク取得用の環境を構築しました。
- Number of Warehousesは40(CPUコア数×10)
- Virtual Users to Build Schemaは8(CPUコア数×2)
- 実行するDriverScriptのオプションは以下の通りです。
- 「Timed Test Driver Script」にチェック
- Minutes of Rampup Timeを2に
- Minutes for Test Durationを5に
- Use All Warehousesにチェック
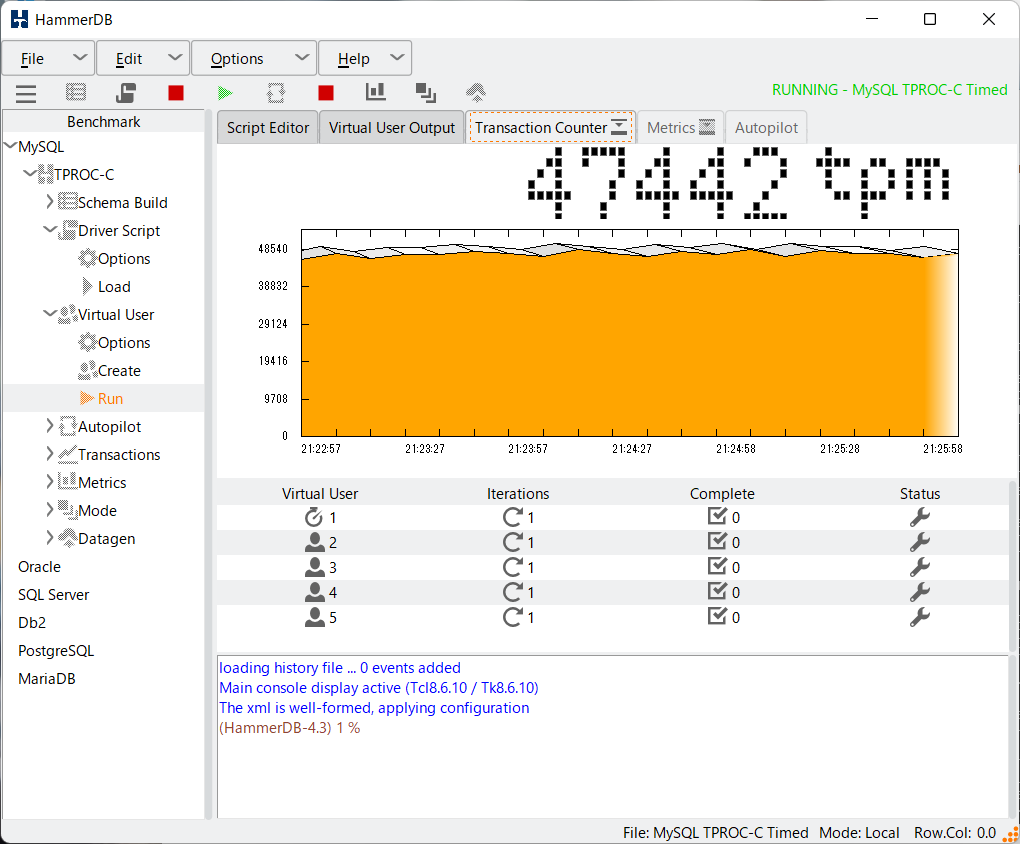
結果、こうなりました
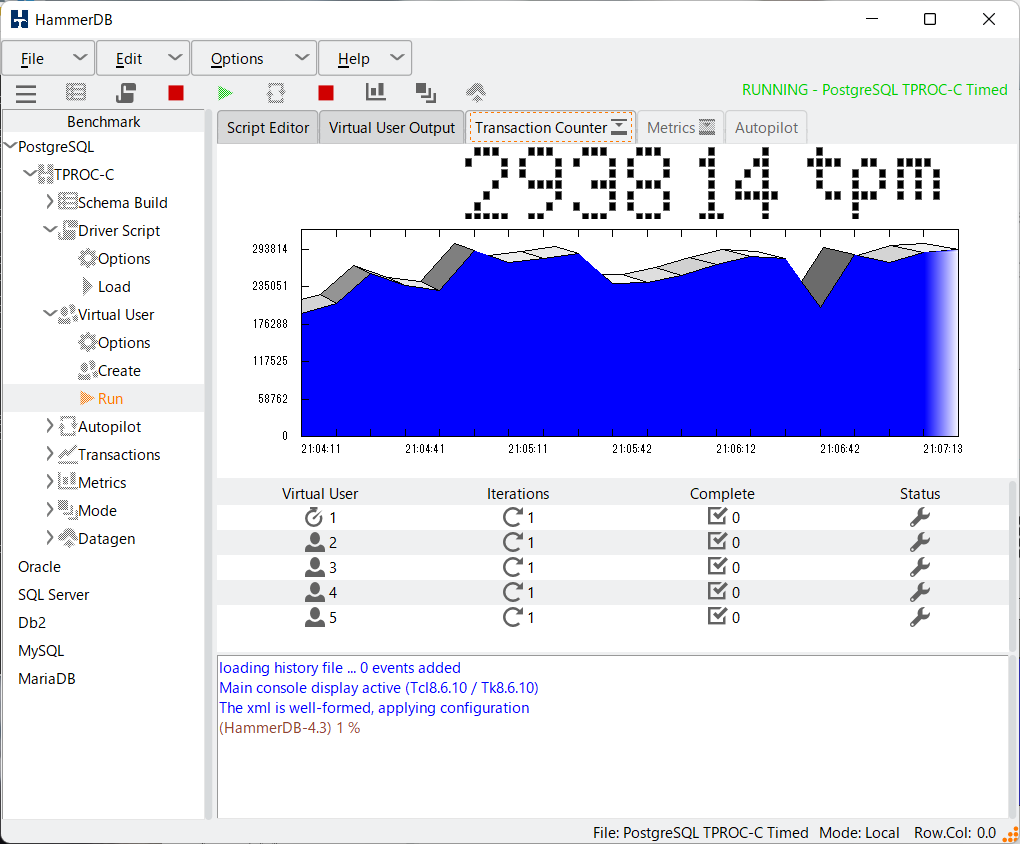



第3位 MySQL 8.0.27( 46,292 tpm )

まとめ
今回も大差でPostgreSQLがトップでした。チューニングした結果とはいえ、VMのOSはCentOSからDebianへ変更しました。
ホストのマシンもスペックアップした結果、ここまでスコアを上げることができました。
MySQLだけはなぜか思うような結果にはなりませんでしたが…。
動作している印象では、CentOSよりはDebianの方が相性は良さそうな感触を受けました。
パフォーマンスチューニングも奥が深いので、これからも突き詰めていきたいと思います。
まだまだ新型コロナの感染は広がっていて油断はできない状況ですが、こうして家にいる時間を楽しむ方法はたくさんあります。
こういう時期を使って、スキルアップをしていきたいですね!
それでは!
これからを歩き出すエンジニアの皆さんへ
春ですね!
私は2021年4月でエンジニアとして歩み始めてから丸19年。今年で20年目を迎えます。
先輩の背中を追いかけてきたはずですが、気づいたら背中を見せる側になってきました。 ありがたいことに、私のことを慕ってくれる後輩さんも出てきてくれました。
今は4月、新たなスタートを切る人たちもたくさんいらっしゃるでしょう。
今日は、そんな皆さんへ向けた、人生のちょっと先を行く先輩からの
ほんのちょっとのアドバイスです。
まずはひと言。
「仕事は人とするものです。」
パッと聞くと、「当たり前じゃん」って思う人もいると思います。
でも、私が19年、エンジニアという仕事をしてきて思った、ひとつの結論がこれでした。
仕事をするということは、その仕事を任せてくれた人がいます。
そして、自分の仕事の結果を必要としている人がいます。
ITのエンジニアをしていると、目の前はモニターで、Slackなどのメッセージアプリからのテキスト越しの会話が流れ、
人によっては画面いっぱいのコードを見つめる人もいるでしょう。
どうしても、人と直接会話をする機会が減る分、コミュニケーションが軽く薄いものに感じてしまいがちです。
でも、先にお伝えしたとおり、仕事というのは、自分が成果を出すことを信じて任せてくれる人がいて、
自分の成果を必要とする人がいます。
自分のする仕事というのは、その人達のためにあるものだと、私は思うのです。
エンジニアにとっての一番の褒め言葉
今まで仕事をしてきて、一番嬉しかった褒め言葉があります。それは、
「また一緒に仕事がしたい」
でした。
自分の技術や知識ではなく、一緒に仕事をしていた時の姿勢だったり、普段の行動だったり、
人としての立ち居振る舞いを見てくれていたのだな、と思いました。
何より、自分を必要としてくれているのが嬉しかったんです。
これからを担っていく皆さんも、こういう褒め言葉をいただけるエンジニアになりませんか?
成果に焦る必要は無いです
先輩方も同じ道を通っています。
同期や後輩の方が先に良い成果を出したりして、自分もいっぱい仕事して成果を出さなきゃ!と
焦る気持ちが出てくるかもしれません。
でも、焦ることなんて無いんです。先輩方も、皆さんと一緒に仕事をすることが楽しみでしょうがないはずです。
成果よりも、人間性を見てくれている先輩はたくさんいらっしゃいます。
人によっては不器用でそれを上手く伝えられないだけ。
根本的には、一緒に楽しく仕事をしたいだけなのですから。
最後にもう一度
最後にもう一度、お伝えします。
「仕事は人とするものです。」
これからのエンジニア人生、「一緒に仕事をしたい」と思える人と沢山仕事をしてください。
たくさんの人たちと言葉を交わしてください。
それが、仕事というものの醍醐味のひとつです。
どうぞ焦らず、一歩ずつ、しっかりと。でも、楽しく。
一人でも多くのエンジニアの皆さんが、笑顔で輝かしい未来に出会えますように。
MariaDB 10.2のインストールと初期セットアップ
※この記事は[Qiita](https://qiita.com/sugat1679/items/4f76eb2a6c07d9e13a0d)の記事をエクスポートしたものです。内容が古くなっている可能性があります。
#MariaDB 10.2のインストールと初期セットアップ
今回は、ほぼ自分向けでもありますが、MariaDBのインストール手順を書き起こしていきたいと思います。
え?インストールなんて「yum install MariaDB-server」だけで良いんじゃないの?
っていうそこのアナタm9!!
ほぼ自分向けですから!
# インストール環境
OS … CentOS 7.4
DB … MariaDB 10.2.x(最新バージョン)
# いざ、インストール
## yum リポジトリの追加
リポジトリジェネレータを使い、リポジトリのエントリ情報を取得し、

/etc/yum.repos.d/にMariaDB.repoという名前で保存してください。
```shell
$ cat /etc/yum.repos.d/MariaDB.repo
# MariaDB 10.2 CentOS repository list - created 2017-12-15 08:42 UTC
# http://downloads.mariadb.org/mariadb/repositories/
[mariadb]
name = MariaDB
baseurl = http://yum.mariadb.org/10.2/centos7-amd64
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
gpgcheck=1
```
## インストール
・既存のMariaDBがインストールされていれば削除します
```shell
$ yum -y remove MariaDB-server MariaDB-client
```
・MariaDBのインストール
```shell
$ yum -y install MariaDB-server MariaDB-client
```
## データディレクトリの作成
インストールが完了したら、データファイルを配置する先を準備します。
(今回の例では、/export/mariadbをデータファイルの配置先とします。)
```shell
mkdir /export/mariadb
chown mysql:mysql /export/mariadb
```
ちなみに、yumでインストールが完了すると、mysqlグループとユーザーが作成されていますので、
データファイルの配置先をデフォルト以外に設定したい場合は上記手順のような感じで
mysqlユーザーが所有者となっているディレクトリを作成してください。
デフォルトの `/var/lib/mysql/data` 配下で良い場合は何もしなくて結構です。
## 設定ファイルのコピー
`/usr/share/mysql` 配下に `my-XXXXX.cnf` というファイルが幾つか存在します。
デフォルトで用意されたmy.cnfのサンプルです。
インストールするサーバーのスペックや利用するサービス等の規模によって適宜選択し、
`/etc`の直下にコピーしましょう。
```shell-session
# ls -l /usr/share/mysql/my*.cnf
- rw-r--r-- 1 root root 4920 9月 25 15:39 /usr/share/mysql/my-huge.cnf
- rw-r--r-- 1 root root 20441 9月 25 15:39 /usr/share/mysql/my-innodb-heavy-4G.cnf
- rw-r--r-- 1 root root 4907 9月 25 15:39 /usr/share/mysql/my-large.cnf
- rw-r--r-- 1 root root 4920 9月 25 15:39 /usr/share/mysql/my-medium.cnf
- rw-r--r-- 1 root root 2846 9月 25 15:39 /usr/share/mysql/my-small.cnf
# cp -p /usr/share/mysql/my-small.cnf /etc/my.cnf.d/server.cnf
```
my.cnfのコピーが完了したら、ざっくりの設定項目を変更します。
```shell-session
[mysqld]
datadir = /export/mariadb
innodb_data_home_dir = /export/mariadb
innodb_log_group_home_dir = /export/mariadb
innodb_buffer_pool_size = #トータルのメモリの半分~7割程度に
transaction-isolation = READ-COMMITTED # トランザクション分離レベル
innodb_flush_method=O_DIRECT # ファイルへのフラッシュ方法
# REDOログ関係
innodb_log_file_size = # innodb_buffer_pool_size の 25%に
innodb_log_buffer_size = # innodb_log_file_sizeの50%に(※要検証)
innodb_log_files_in_group = 2 # 1グループあたりのログファイルの数(※要検証)
innodb_page_size = 16K # innodbページサイズ(デフォルト16K)
innodb_io_capacity = 2000 # I/O効率化
innodb_flush_neighbors = 0 # I/O効率化
character-set-server = utf8mb4 # キャラクターセット
```
他の項目は適宜環境に合わせて変更してください。
## サービスの起動
```shell-session
# systemctl start mariadb.service
```
## サービスの正常性確認
```shell-session
# systemctl status mariadb.service
```
## 自動起動の設定
```shell-session
# systemctl enable mariadb.service
```
## 初期設定ツールの実行
```shell-session
# mysql_secure_installation
```
```shell
- Enter current password for root(enter for none):
(初期のrootのパスワードを聞かれるのでそのままEnter)
- Set root password?[Y/n]
(新しいrootパスワードを設定)
- Remove anonymous users?[Y/n]
(anonymousユーザーを削除するか聞かれるのでYes)
- Disallow root login remotely?[Y/n]
(rootユーザーのリモートアクセスを許可するか聞かれるのでNo)
- Remove test database and access to it?[Y/n]
testデータベース消す?って聞かれるのでYes
- Reload privilege tables now?[Y/n]
設定読み込み直す?って聞かれるのでYes
```
で完了です。
## Spiderストレージエンジンのインストール
```shell-session
# mysql -uroot -p < /usr/share/mysql/install_spider.sql
```
これで一通りの準備が完了します。
MariaDBのストレージエンジンを駆使して目指せRDS ~ 俺達の戦いはここからだ ~
※この記事はQiitaの記事をエクスポートしたものです。内容が古くなっている可能性があります。
はじめに
どぉ~もみなさん、おはこんばんにちは!
さて、今回は前回の続きとなります。 MariaDBのSPIDERストレージエンジンのフェデレーションの紹介とSPIDERノードの冗長化に関する検証を行っていきたいと思います!
おさらい(目指している環境)
今、僕が実現させていきたいと目指している環境の縮図はこちらです。
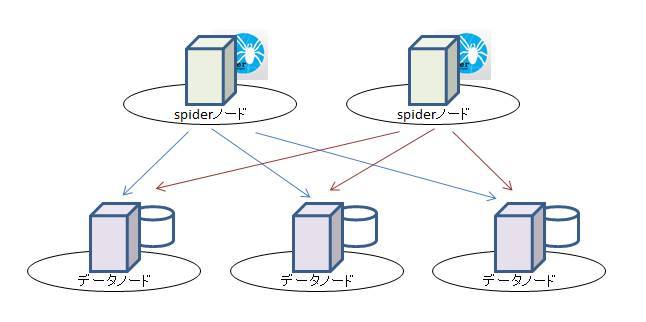
最近特に聞く話で「マイクロサービス化」というテーマがあります。 サービス単位でアプリケーション、DBのサーバを纏め、サービス同士が密結合しないような構成にしよう、というものです。 そうした場合、DB側で発生するものはというと、別のサーバにあるDBのテーブルを参照したいという要求を解決しなくてはならない事が多いと思います。 この問題を実現するために、レプリケーションを使って別サーバとデータを同期させて…なんていう対応はよくあると思います。 でもこれには、データ量が増えていく&レプリケーションさせたいテーブルが増えていくと、 今度はレプリケーションに負荷がかかることでデータの同期遅延が発生し、 結局は解決できなくなって有耶無耶に…なんて話になりがちです。 「これ、ちょっとレプ(リケーション)してくんない?」とさらっと言われて「そんなに簡単に言うなよ…」と暗黒面に落ちそうになったことは数え切れないです。 そこで、レプリケーションと違う形で他のDBを簡単に参照し、尚且つSQLで表結合できるようなものってないのかな?と探していたところに出会ったのが、 このMariaDBのストレージエンジン「SPIDER」だった、というお話ですね。
今描いている理想図を実現するために必要なことで、まだわかっていないことがありました。
- フェデレーションってどうやってやるんだっけ?
- バックアップってどうなるの?
- SPIDERノードってどうやって冗長化させるの?
今回はそんなお話です。
【検証その1】フェデレーションってどうやってやるんだっけ?
フェデレーションは、外部のDBサーバのテーブルをあたかも自分のところにいるかのような事ができる機能です。 所轄「リンクテーブル」といったところでしょうか。
まずはSPIDERノードのDBに対して、create server文を実行し、サーバーを登録しておきます。
create server mariadbdata01 foreign data wrapper mysql options (user 'spider', password 'XXXXX', host '192.168.110.133', port 3306); create server mariadbdata02 foreign data wrapper mysql options (user 'spider', password 'XXXXX', host '192.168.110.134', port 3306); create server mariadbdata03 foreign data wrapper mysql options (user 'spider', password 'XXXXX', host '192.168.110.135', port 3306);
この状態で、データノード03(↑の例でいうとmariadbdata03)上に通常のInnoDBベースのテーブルを作成し、データを登録します。
use example; create table depts( dept_id int primary key, dept_name varchar(32) ) engine = InnoDB; insert into depts(dept_id,dept_name) values(1,'営業部'); insert into depts(dept_id,dept_name) values(2,'経理部'); insert into depts(dept_id,dept_name) values(3,'技術部'); insert into depts(dept_id,dept_name) values(4,'法務部');
よくある部署テーブルです。
そして、SPIDERノードのサーバー上に通常のInnoDBベースのテーブルを作成します。
use example; create table employees( id int primary key auto_increment, dept_id int, name varchar(32) ) engine = InnoDB; insert into employees(dept_id,name) values(1,'田中'); insert into employees(dept_id,name) values(2,'玉木'); insert into employees(dept_id,name) values(3,'鈴木'); insert into employees(dept_id,name) values(3,'山本'); insert into employees(dept_id,name) values(2,'斉藤'); insert into employees(dept_id,name) values(1,'佐藤'); insert into employees(dept_id,name) values(1,'小澤'); insert into employees(dept_id,name) values(2,'関野'); insert into employees(dept_id,name) values(0,'中村');
よくある社員テーブルですね。 この状態では、部署テーブルは別サーバー上にあるため、表結合することはできません。 そこで、SPIDERエンジンのフェデレーションを使って、テーブルを作成します。
create table depts( dept_id int primary key, dept_name varchar(32) ) engine = SPIDER comment='wrapper "mysql", srv "mariadbdata03"';
こうすることで、データノード03上のテーブルを参照する準備ができました。 それでは、実際に部署テーブルと社員テーブルを結合してみましょう。
select a.name , b.dept_name from employees a left join depts b on a.dept_id = b.dept_id ; +--------+-----------+ | name | dept_name | +--------+-----------+ | 田中 | 営業部 | | 玉木 | 経理部 | | 鈴木 | 技術部 | | 山本 | 技術部 | | 斉藤 | 経理部 | | 佐藤 | 営業部 | | 小澤 | 営業部 | | 関野 | 経理部 | | 中村 | NULL | +--------+-----------+ 9 rows in set (0.02 sec)
特殊なSQLを書く必要なく素直に結合することができました。 現状この機能はMariaDB、MySQL、Oracleで利用可能とのことです。
SPIDERの機能を使うと、データの分散と集約が簡単に実装できることがわかりました。
【検証その2】バックアップってどうするの?
ひとまず、SPIDERストレージエンジンで作成したテーブルを含むデータベースを普通にバックアップしてみましょう。
mysqldump -uroot -p -A > spider_all_db.sql more spider_all_db.sql
-- -- Table structure for table `depts` -- DROP TABLE IF EXISTS `depts`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!40101 SET character_set_client = utf8 */; CREATE TABLE `depts` ( `dept_id` int(11) NOT NULL, `dept_name` varchar(32) DEFAULT NULL, PRIMARY KEY (`dept_id`) ) ENGINE=SPIDER DEFAULT CHARSET=utf8 COMMENT='wrapper "mysql", srv "mariadbdata03"'; /*!40101 SET character_set_client = @saved_cs_client */; -- -- Table structure for table `employees` -- DROP TABLE IF EXISTS `employees`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!40101 SET character_set_client = utf8 */; CREATE TABLE `employees` ( `id` int(11) NOT NULL AUTO_INCREMENT, `dept_id` int(11) DEFAULT NULL, `name` varchar(32) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8; /*!40101 SET character_set_client = @saved_cs_client */; -- -- Dumping data for table `employees` -- LOCK TABLES `employees` WRITE; /*!40000 ALTER TABLE `employees` DISABLE KEYS */; INSERT INTO `employees` VALUES (1,1,'田中'),(2,2,'玉木'),(3,3,'鈴木'),(4,3,'山本'),(5,2,'斉藤'),(6,1,'佐藤'),(7,1,'小澤'),(8,2,'関野'),(9,0,'中村'); /*!40000 ALTER TABLE `employees` ENABLE KEYS */; UNLOCK TABLES; DROP TABLE IF EXISTS `products_partition`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!40101 SET character_set_client = utf8 */; CREATE TABLE `products_partition` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) NOT NULL, `price` int(11) NOT NULL DEFAULT 0, `created_at` datetime NOT NULL, `updated_at` datetime DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=SPIDER AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4 PARTITION BY HASH (`id`) (PARTITION `p1` COMMENT = 'server "mariadbtest02", table "products_partition"' ENGINE = SPIDER, PARTITION `p2` COMMENT = 'server "mariadbtest03", table "products_partition"' ENGINE = SPIDER, PARTITION `p3` COMMENT = 'server "mariadbtest04", table "products_partition"' ENGINE = SPIDER);
どうやら、InnoDBで作られたテーブルも、SPIDERエンジンで作られたテーブルも作られたようです。
【検証その3】SPIDERノードってどうやって冗長化させるの?
それではこのダンプしたSQLを使って、新しくSPIDERノードのサーバを立て、インポートしてみます。
[user@mariadb-spider02 ~]$ mysql -uroot -p < spider_all_db.sql Enter password: ERROR 1477 (HY000) at line 33: The foreign server name you are trying to reference does not exist. Data source error: mariadbdata03
mariadbdata03 がいないよ、と怒られました。
中身を見ていくと、mysqlシステムテーブル内のデータは最後に登録されるようなので、そこでエラーになっているようです。
どうやら試行錯誤する必要がありそうです。
検証結果まとめ
今回の検証結果です。
- 【検証その1】フェデレーションってどうやってやるんだっけ?
- create server文で予めサーバを登録しておくことで、create table 文のコメントに `wrapper` で指定してあげることで簡単に外部のサーバーのテーブルを登録することができ、 尚且つ自身のテーブルであるかのように結合することができました。
- 【検証その2】バックアップってどうするの?
- 特に特殊な操作も必要なく、mysqldumpコマンドでバックアップすることが可能である事がわかりました。
- 【検証その3】SPIDERノードってどうやって冗長化させるの?
- 単純にmysqldumpコマンドでバックアップしたテーブルをインポートするだけではエラーになるため、何か他の作業が必要そうであることがわかりました。
最後に
今回ご紹介したSPIDERストレージエンジンのフェデレーションだけでなく、MariaDBにはConnectというストレージエンジンが存在していて、 これを利用するとODBC経由で別のRDBMSも接続することが可能になる事まではわかっています。 なので、これらの機能を使うことで、マイクロサービス化したサービスのDBサーバや、まだサービス移行途中の旧システムのDBなどもMariaDB経由で参照することができます。 こうすることで、アプリケーション側が「どのDBに接続すればどのデータが見れる」ということを意識せずにデータを利用する環境が整い、 またサーバーの負荷状況に合わせてスケールアウトも容易にできるのではないでしょうか。
まだ私自身、DBAとしてもまだまだなので、もっとデータベースのことを検証し、知見を高め、 うちには優秀なDBAがいる。だから良いサービスが提供できる と周囲のエンジニアの皆さんから評価していただけるようなDBAを目指していきたいと思います!
MariaDBのストレージエンジンを駆使して目指せRDS ~ はじめの一歩 ~
※この記事はQiitaの記事をエクスポートしたものです。内容が古くなっている可能性があります。
はじめに
どぉ~もみなさん、おはこんばんにちは! 飲み会が近づくと体調が悪くなる と定評(?)の@sugat1679です。 アイスタイルでDBA業務をし始めて2年目。だいぶ板についてきました。 忘年会シーズンになりましたね。皆さん、体調にはお気をつけくださいね!(ゴホッゴホッ
そこで、いろいろなDBを触ってきた私の今までの経験から、これからのデータベースサーバーを取り巻く環境で こんな構成が取れたら良いのでは?という話から、現在注目しているMariaDBについて、 ストレージエンジンにフォーカスを当ててお話していきます。
目指したい、理想のデータベース構成
今まで見てきたデータベースの中で、「これはすごい!」と衝撃を受けたのは、 Microsoft社のSQL Serverの機能である「AlwaysOn 可用性グループ」というものでした。 それぞれのサーバーでデータを同期しつつ、それぞれが独立していて利用できる。 尚且つ、スケールアウトも簡単。
昨今のデータベース事情を見ていくと、「このサーバーなら絶対に落ちない」というような構成よりも、 柔軟に拡大・縮小でき、かつ任意のデータを同期させるような構成が取れたら一番良いなと感じています。
なので、私の考えている理想のデータベース構成となるポイントは以下の3つです。 ・スケールアウトが容易にできる →一時的な負荷増大や、場合によってはDRとして使えるような ・データの同期が簡単 →どのデータベースが持つレプリケーション機能も一長一短で、いろんなエラーに苦しめられます ・運用のコストが低い →どの企業のDBAさんも人数が少ない会社が多いと思います。少ない人数で運用していく中で 複雑な機能は使いたくないし、緊急事態で自分が動けないときに別の人でも初動対応できるようなものがいいです。
今回のブログのタイトルにもある、AmazonさんのRedShiftやAuroraといったデータベースは まさにその理想を実現する形じゃないかと考えています。
私もいちエンジニアなんですね。これらを見た時に、「これを自分で実現するならどうやったらできるのか?」って 思ってしまったんです。思ってしまったならしょうがない!やってみよう!と。
先日、私が毎年参加している「db tech showcase」という カンファレンスにて、こんなセッションを聞いてきました。 「MariaDB 10.3から利用できるSpider関連の性能向上機能・便利機能ほか 」 https://www.slideshare.net/Kentoku/mariadb-103spider
また、関連している情報を調べていくと、こんな記事を見つけたのです。 「OSSのカラム型DBはここまで進化! インサイトテクノロジー・小幡一郎氏」 http://ascii.jp/elem/000/001/511/1511229/index-2.html
この記事を見たときに思いました。
このストレージエンジンを使えば理想のデータベース構成に近づけるのでは と。
そんな構成が実現できないか、を日々研究している毎日です。
MariaDBのストレージエンジンについて
ご存じの方も多いですが、MySQLのフォークから生まれたMariaDBは、「ストレージエンジン」と言って データベースのエンジン部分をプラグイン形式で使い分けることができます。 ・InnoDB…一番メジャーなストレージエンジン。トランザクションをサポート ・CONNECT…異なるRDBMS(Oracleとか、SQLServerとか)にも接続できるストレージエンジン ・SPIDER…シャーディング(分割)やフェデレーション(外部接続)を実現 ・ColumnStore…カラム型(列志向型)データベースエンジン
これらを組み合わせることで、理想としている構成が組めないか考えました。 そこで私が注目したのが、SPIDERとConnect、ColumnStoreのストレージエンジンの組み合わせです。 今回はこれらのうち、「SPIDER」ストレージエンジンについてご紹介します。
ストレージエンジン「SPIDER」について
SPIDERと呼ばれるストレージエンジンは、記事にかかれている通り、シャーディングとフェデレーションを提供する ストレージエンジンです。 このストレージエンジンの詳細については、私が説明するよりもこちらのSlideShareが詳しく書かれているので 説明については割愛させていただきます。 参考URL: 「Spiderストレージエンジンのご紹介」スパイラルアーム合同会社 斯波建徳様 https://www.slideshare.net/Kentoku/spider-70345615
今回はこんな構成を組んでみました。

SPIDERストレージエンジンで実現できるのは、「シャーディング(レコードの分散)」と、「H/A(高可用性)」、「フェデレーション(外部サーバのテーブルを接続)」です。
SPIDERストレージエンジン機能その1「シャーディング」
試しに、この構成でシャーディングを実現させてみます。 (予め、create server文を使ってデータノード用のサーバーは登録済みとします) Spiderノードで以下のSQLを実行します:
create table products_partition ( id int AUTO_INCREMENT NOT NULL, name varchar(255) not null, price int(11) not null default 0, created_at datetime not null, updated_at datetime, primary key (id) ) ENGINE = SPIDER default character set = utf8mb4 partition by hash (id) ( partition p1 comment 'server "mariadbtest02", table "products_partition"', partition p2 comment 'server "mariadbtest03", table "products_partition"', partition p3 comment 'server "mariadbtest04", table "products_partition"' );
ENGINE = SPIDER という句が書かれているのがわかります。
また、partition by 句の中に comment としてどのサーバのどのテーブルに振り分けるか、を定義するのが特徴となっています。
次に、データノード(3台すべて)で以下のSQLを実行します:
create table products_partition ( id int AUTO_INCREMENT NOT NULL, name varchar(255) not null, price int(11) not null default 0, created_at datetime not null, updated_at datetime, primary key (id) ) ENGINE = InnoDB default character set = utf8mb4;
こちらは、普通のcreate table文ですね。 ここまでで準備は完了です。
試しにSpiderノードに接続して、データを登録していきます。
insert into products_partition(name, price, created_at) values ('えだまめあられ', 108, NOW()); insert into products_partition(name, price, created_at) values ('マイクポップコーン', 216, NOW()); insert into products_partition(name, price, created_at) values ('ルマンド', 324, NOW()); insert into products_partition(name, price, created_at) values ('エリーゼ', 324, NOW()); insert into products_partition(name, price, created_at) values ('カントリーマアム', 324, NOW()); insert into products_partition(name, price, created_at) values ('いちごビスケット', 216, NOW()); insert into products_partition(name, price, created_at) values ('ポテトチップス のり塩味', 150, NOW()); insert into products_partition(name, price, created_at) values ('ポテトチップス コンソメ味', 150, NOW()); insert into products_partition(name, price, created_at) values ('ポテトチップス うすしお味', 150, NOW()); insert into products_partition(name, price, created_at) values ('海苔巻きせんべい', 324, NOW()); insert into products_partition(name, price, created_at) values ('ごませんべい', 324, NOW());
すると、

データがキレイに登録されました。 これを各データノードに直接接続してテーブルの中身を見てみると…

ID列をキーにしてレコードが分散されているのがよくわかります。 このように、create tableのcomennt文を使って簡単にデータが分散できるというのがシャーディングです。
SPIDERストレージエンジン機能その2「H/A(高可用性)」
この機能は、簡単に言えば「テーブルの複製を別のサーバーに置く」という機能です。
まずはSpiderノードにてテーブルを作成します:
create table products_ha ( id int AUTO_INCREMENT NOT NULL, name varchar(255) not null, price int(11) not null default 0, created_at datetime not null, updated_at datetime, primary key (id) ) ENGINE = SPIDER default character set = utf8mb4 comment 'table "products_ha", server "mariadbtest02 mariadbtest03"' ;
comment句がちょっと変わりました。
次に、データノードでテーブル作成します。
(こちらは、先ほどと同様にInnoDBで作成する普通のテーブルのため、SQLは割愛します)
そして、データを登録すると…:
 キレイに複製されていることがわかります。
ここでちょっと試したいことがあったので、以下のALTER文をSpiderノードにて投げてみました。
キレイに複製されていることがわかります。
ここでちょっと試したいことがあったので、以下のALTER文をSpiderノードにて投げてみました。
alter table products_ha comment 'table "products_ha", server "mariadbtest02 mariadbtest03 mariadbtest04"';
サーバーを追加したらどうなるのかな?という挙動を試したかったのです。
そして、Spiderエンジンの管理用テーブルspider_tablesを見てみると、
 ちゃんと追加されてました。
そして更に、管理コマンドspider_copy_tablesを実行すると…
ちゃんと追加されてました。
そして更に、管理コマンドspider_copy_tablesを実行すると…
 見事に新たなデータノードにコピーが成功しました。
見事に新たなデータノードにコピーが成功しました。
もう少し検証は必要ですが、こういった使い方もできる、というのがわかりました。 テーブル単位でちょっとしたレプリケーション代わりにも使えそうです。 (本当は、監視ノード登録したりとか、いろいろ設定するとサーバーダウンの自動検知とかいろいろやってくれそうです)
まとめ(次回へ続く?)
MariaDBのSpiderエンジンを使うことで、データをテーブル単位・サーバー単位で振り分けられることがわかりました。 次は、ConnectエンジンやSpiderエンジンのフェデレーション機能を使って集約する機能について検証していきます。
DBサーバーの監視ツールって使いづらい
※この記事はQiitaの記事をエクスポートしたものです。内容が古くなっている可能性があります。
はじめに
この投稿はアイスタイル アイスタイル Advent Calendar 2016の25日目の記事です。
なんだか、皆さん遠慮しがちで最終日だけポカーンと空いていて、「どうするどうするー?」なんて言っていたら、
某新人さん「こんな時こそchoiceですよ!」
ワタシ「(みんな大変そうだなぁ)」
hubotさん「厳正な抽選の結果、@sugatに決まりました」
ワタシ「えぇぇぇぇ」
というお約束的なパターンでトリを務めさせていただきます。 9月に入社した新米DBAの@sugat1679です。よろしくお願いします。
最終日の記事ということで、(主に内部の方々の)期待が大きくなりつつありますが、 DBAですし、SQL Serverの監視ツールについてなんぞをお話していきます。
ところで、今日は12月25日。クリスマスですね! リア充のみなさん、
「きのうは、おたのしみ でしt(ry」 (言ってて寂しくなってくるからやめよう)
背景
前職でも社内SEとしてデータベースの管理を中心にお仕事していましたが、 DBサーバの監視ツールが使いづらいものが多く、「これ!」という良いツールが見つからなかったので 自作してしまいました。 今回は、そのご紹介です。
DBサーバの監視ツールって
基本的にはどのツールも機能的には遜色のないものになっていて、 ・リソース監視 ・クエリー監視 ・ブロッキング監視 等がリアルタイムで可視化されて、1台のサーバーの情報が細かく見れるものが多いです。 有名なところだと、DELL社のSpotlightとか、インサイトテクノロジー社のPISOとかがそれですね。
でも…
DBサーバの運用って、1台で行われるわけではないですし、更新系と参照系に分かれていて レプリケーション等の同期ツールでデータを同期したり、ミラーリングやクラスタリングで 冗長化構成を取っていたりして、サーバ1台だけ深く見ていっても解決できない問題が多いのが 現状だと思います。 そして、
それ(監視ツール)、お高いでしょう?
DBサーバのトラブル対応って
大きく分けて、以下の2つに分類されます。 ・レスポンスが悪い →重たいクエリが実行中でサーバーが高負荷状態 →予期せぬ時間帯にデータが大量に流入 →誰かがテーブルロックしちゃってる →いつもはすぐに返ってくるクエリが返ってこなくなった
・サーバーにつながらない →CPU使用率100%のまま張り付き状態 →ディスクがいっぱいで書き込みできない →497日問題(Windows Server 2008とか)
トラブル発生!最初にやること
私は、DBサーバのトラブルが発生した場合、以下の3つを確認します。
- サーバーのリソース(CPU / メモリ / HDD)の状態を確認
- 実行中のクエリを確認
- 関係するサーバーの状態を確認
なので、1台のサーバーの深い情報は必要ではなく、複数台のサーバーにおいてどんな状態なのか?が 一目で確認できるツールが欲しい、と考えました。
そこで生まれたのは、自作の監視ツール「DBKeeper」
昨今のDB監視ツールについて調査していたところ、どれもサーバ1台に深く潜り込む物が多く、
自分の要望をかなえるツールが見当たりませんでした。
そしたら、誰かにささやかれたんです。
「じゃあ、自分で作っちゃえばいいじゃん」
と。
そうして生まれたのが、データベース監視ツール「DBKeeper」です。

サーバー1台あたりで「CPU」「メモリ」「キャッシュのヒット率」「ブロッキング」の状態がひと目にわかる情報を表示し、 それを4つの枠で一度に4台分のサーバーが監視できます。 プログラムは、C#.NetとWPF(Windows Presentation Foundation)というUIサブシステムで作りました。 1台分の枠をコントロール化させているので、画面の解像度やサイズによっていくつも増やせる仕様です。 画面のデザインは、車が好きなので車のメーターパネルを意識して作りました。
機能その1「ブロッキングツリー」
SQLServerはブロッキング(データの更新などでロックがかかってしまい、そのテーブルへのアクセス待ちが発生すること)が よく発生するので、その事象を発生元から何の処理に影響を与えているのか、ツリー構造で表示させたいと思いました。 また、そのセッションの強制終了も可能です。
機能その2「セッションリスト」
SQLServer Management Studioでおなじみの「利用状況モニター」と同等のものです。 一度繋がったセッションのリストを表示できます。
機能その3「実行中のクエリリスト」
CPU負荷のグラフと一緒に、1秒おき、3秒おき、5秒おきに動的管理ビューを使って実行中のクエリを表示する、というものです。 主にパフォーマンス解析などに役立てます。
大きな機能としては、実はこの3つしか存在してません。 というのも、先程もお話したとおり、トラブル対応の初動捜査に必要なものはこれだけだからです。
※どうやら私はQiitaでの投稿が初の為、画像のアップロードに制限がかかっているようです。 もうちょっと画面を紹介しながら説明できれば…と思ったのですが、申し訳ございません。
使用しているSQLご紹介
画像が使えないっぽいので、せめてSQLだけでも紹介していきますね。
CPU使用率取得
パフォーマンスカウンタの値をSQLで取得するというちょっと変わった代物です。
-- ※10行目と15行目にはインスタンス名を入れること!! select perfCount.object_name , perfCount.counter_name , perfCount.instance_name , case when perfBase.cntr_value = 0 then 0 else ( cast ( perfCount.cntr_value as float ) / perfBase.cntr_value ) * 100 end as cntr_Value from ( select top 1 * from sys.dm_os_performance_counters where object_Name = 'SQLServer:Resource Pool Stats' and counter_name = 'CPU Usage %' ) perfCount inner join ( select * from sys.dm_os_performance_counters where object_Name = 'SQLServer:Resource Pool Stats' and counter_name = 'CPU Usage % base' ) perfBase on perfCount.Object_name = perfBase.Object_name and perfCount.instance_name = perfBase.instance_name where perfCount.instance_name = 'internal';
メモリ使用率取得
これもまた、パフォーマンスカウンタの値をSQLで取得するというものです。 これは、SQLServer用に確保されているメモリの中で、さらに今の使用状況が見れるので、 インスタンス起動直後に見るとすごい低い数値なのですが、時間がたつにつれて上がっていく様子が見れるので 面白いです。
-- 8行目と12行目にはインスタンス名を入れること SELECT a.cntr_value as MemoryInUse , (a.cntr_value * 1.0 / b.cntr_value) * 100.0 AS MemoryUseage FROM sys.dm_os_performance_counters a JOIN (SELECT cntr_value,OBJECT_NAME FROM sys.dm_os_performance_counters WHERE counter_name = 'Target Server Memory (KB)' AND OBJECT_NAME = 'SQLServer:Memory Manager' ) b ON a.OBJECT_NAME = b.OBJECT_NAME WHERE a.counter_name = 'Total Server Memory (KB)' AND a.OBJECT_NAME = 'SQLServer:Memory Manager'
キャッシュヒットレート(バッファーキャッシュ、プロシージャキャッシュ)
バッファーキャッシュヒットレート
-- 7行目と11行目にはインスタンス名を入れること SELECT (a.cntr_value * 1.0 / b.cntr_value) * 100.0 AS BufferCacheHitRatio FROM sys.dm_os_performance_counters a JOIN (SELECT cntr_value,OBJECT_NAME FROM sys.dm_os_performance_counters WHERE counter_name = 'Buffer cache hit ratio base' AND OBJECT_NAME = 'SQLServer:Buffer Manager' ) b ON a.OBJECT_NAME = b.OBJECT_NAME WHERE a.counter_name = 'Buffer cache hit ratio' AND a.OBJECT_NAME = 'SQLServer:Buffer Manager'
プロシージャキャッシュヒットレート
-- 7行目と12行目にはインスタンス名を入れること SELECT (a.cntr_value * 1.0 / b.cntr_value) * 100.0 AS ProcedureCacheHitRatio FROM sys.dm_os_performance_counters a JOIN (SELECT cntr_value,OBJECT_NAME FROM sys.dm_os_performance_counters WHERE counter_name = 'Cache Hit Ratio Base' AND OBJECT_NAME = 'SQLServer:Plan Cache' AND instance_name = 'SQL Plans' ) b ON a.OBJECT_NAME = b.OBJECT_NAME WHERE a.counter_name = 'Cache Hit Ratio' AND a.OBJECT_NAME = 'SQLServer:Plan Cache' AND a.instance_name = 'SQL Plans'
まとめ
サーバートラブルが起きると真っ先に疑われるのがデータベースであることが多いです。 実際、私の経験上でも、システムトラブルの大半がデータベース周りの何某かでした。 例えば… ・なんかめっちゃ重たいクエリ流れてる →主な原因:インデックス不足、性能試験してませんでした ・毎日アクセスピーク時に必ずサーバーが応答なしになる →主な原因:DBサーバのパラメータがデフォルトで運用してました (コネクションプールがすぐにいっぱいになってた)
とかとか。
DBサーバの監視って大変だし、トラブルが起きるとエンジニアの技術力が問われるところでもあったりして、 属人化しやすい部分でもあります。 未然に防げればそれに越したことはないですが、やっぱり難しいのも現実問題です。 こうやってツールを作ったり創意工夫して、昨今のシステム運用を安全なものにしていきたいなーと思う 今日この頃でした。
それでは皆さん、良いお年を!
春のDBベンチマーク祭り - TPC-C編 - (2020年版)
みなさんこんにちは!
ご無沙汰してます
約2年前、春のDBベンチマーク祭りと称してMariaDB、MySQL、PostgreSQLそれぞれの
TPC-C(OLTP)、TPC-H(DWH)のベンチマークを取得して比較したものを載せました。
今は新型コロナの影響で自宅にいる時間も多いので、この時間を利用してデータベースの検証を再開したいと思い、
また検証のブログを書きました。
実行環境
今回使用するマシンもご家庭で用意できるPCをホストにしてVMを立て、
そのVMに各OSS DBをインストールして、ベンチマークを取得しました。
〇ホストマシンのスペックはこちら
- CPU : AMD Ryzen 7 3700U 2.3GHz(4core/8thread)
- MEM : 16.0GB
- SSD : NVMe SSD 512GB(SAMSUNG MZVLB512HAJQ)
- GPU : AMD Radeon(TM) RX Vega 10 Graphics
○VMのスペックはこちら
- CPU:4core
- メモリ:8GB
- SSD:64GB
○各RDBのバージョン
- PostgreSQL 11.7
- MySQL 8.0.19
- MariaDB 10.4.12
レギュレーション
今回定めたレギュレーションは以下の通りです
HammerDBを使用したtpc-c実行環境の構築
こちらを参考に、tpc-cベンチマーク取得用の環境を構築しました。
- Number of Warehousesは40(CPUコア数×10)
- Virtual Users to Build Schemaは8(CPUコア数×2)
- 実行するDriverScriptのオプションは以下の通りです。
- 「Timed Test Driver Script」にチェック
- Minutes of Rampup Timeを5に
- Minutes for Test Durationを20に
- Use All Warehousesにチェック
結果、こうなりました
第1位 PostgreSQL 11.7( 66,396 tpm )


第3位 MySQL 8.0.19( 12,810 tpm )

まとめ
今回はPostgreSQLのスコアがダブルスコア以上で上回りました。前回の測定ではとてもその性能を引き出せかったのか、あまり良い数字ではなかったですが、今回は抜群の性能を叩き出しました。
設定したことはメモリに関するチューニングのみ。これだけでここまでの性能を引き出せるとは驚きです。
また、前回と今回では検証したベースの環境が大きく変わっているので、そこも影響があるのかもしれません。
次はTPC-H…とも思いましたが、それぞれのDBに最適なOSってあるのだろうか?というのが気になってきたので、そちらの検証をしてみようと思います。
今は新型コロナの影響で悲しい話や目をそむけたくなる情報ばかりが飛び交っている状況で、僕自身も精神的に参りそうな時期もありました。
でも、こういう時間を有効に活用して、エンジニアとしてのスキルアップを図ったり、エンジニアさん同士のコミュニケーションを活発にして気分転換できたらいいなと思います。
皆でこの状況を乗り越えていきましょう!